Introducing Contextual Retrieval
Contextual Retrieval(文脈的検索)の紹介
はじめに:解決したい課題
AI モデル(ChatGPT や Claude など)は汎用的な知識を持っていますが、特定の会社の情報や専門的なドキュメントについては知りません。例えば:
- あなたの会社の製品マニュアル
- 法律事務所の過去の判例データ
- 社内のFAQドキュメント
これらの情報を AI に「教えて」正確に回答させるための技術が RAG であり、その改良版が今回紹介される Contextual Retrieval です。
第1章:RAGとは何か?(基礎知識)
RAG の正式名称と意味
RAG = Retrieval-Augmented Generation(検索拡張生成)
簡単に言うと:「質問に関連する情報をデータベースから検索して、それを AI に渡してから回答させる」という仕組みです。
なぜ RAG が必要なのか?
方法1:全部プロンプトに入れる
- 知識ベースが小さい場合(約 500 ページ以下)は、全てのテキストをそのまま AI に渡せます
- Claude の「プロンプトキャッシング」機能を使えば、コストも 90% 削減可能
方法2:RAG を使う
- 知識ベースが大きすぎてプロンプトに収まらない場合に必要
- 例:数千ページの法律文書、巨大なコードベースなど
第2章:2つの検索技術を理解する
技術1:Embedding(埋め込み)による意味検索
何をするか: 文章の「意味」を数値ベクトルに変換して、意味的に似ている文章を見つける
例:
- 「犬が公園で遊んでいる」と「ワンちゃんが外で走り回っている」
- 使っている単語は違うが、意味が似ているので近いベクトルになる
得意なこと: 言い換えや類義語を使った検索に強い
苦手なこと: 固有名詞や特定のコードなど、完全一致が必要な検索
技術2:BM25による単語マッチング検索
BM25とは: Best Matching 25の略。単語の一致度に基づいてランキングする古典的な検索アルゴリズム
基盤技術:TF-IDF
- TF(Term Frequency): その単語がドキュメント内に何回出現するか
- IDF(Inverse Document Frequency): その単語がどれだけ珍しいか
BM25はTF-IDFを改良し、文書の長さを考慮し、用語頻度に飽和関数を適用することでこれを改良し、一般的な単語が結果の大部分を占めるのを防ぎます。
例:
ユーザーが「エラーコード TS-999」で検索した場合
- Embedding検索: 「エラー」に関する一般的な文書がヒット
- BM25検索: 「TS-999」という文字列そのものを含む文書を正確に発見
得意なこと: 固有名詞、製品コード、専門用語の完全一致
従来のRAGの仕組み(4ステップ)

【前処理(事前準備)】
1. ドキュメントを小さな「チャンク」に分割
例:1つのPDF → 数百個の短いテキスト断片
2. 各チャンクに対して以下を作成:
- TF-IDFエンコーディング(BM25用)
- セマンティック埋め込み(Embedding用)
【実行時(ユーザーが質問したとき)】
3. BM25で単語の完全一致に基づくTop候補を取得
4. Embeddingで意味的類似性に基づくTop候補を取得
5. 両方の結果をランクフュージョン技術で統合・重複除去
6. 上位Kチャンクをプロンプトに追加してAIが回答生成
第3章:従来RAGの重大な問題
「文脈喪失」問題
ドキュメントを小さなチャンクに分割すると、そのチャンクだけでは何の話かわからなくなるという問題が発生します。
具体例:SEC(米国証券取引委員会)への提出書類
【元の文書】
ACME社 2023年第2四半期 業績報告書
前四半期の売上高は3億1400万ドルでした。
今四半期、会社の売上は前四半期比3%成長しました。
...
【チャンクに分割後】
チャンク#47: 「会社の売上は前四半期比3%成長しました。」
問題点:
- 「会社」ってどの会社?
- 「前四半期」っていつの話?
- このチャンクだけでは文脈が完全に失われている
結果:
「ACME社のQ2 2023の売上成長率は?」と質問しても、このチャンクが正しく検索されない可能性が高い
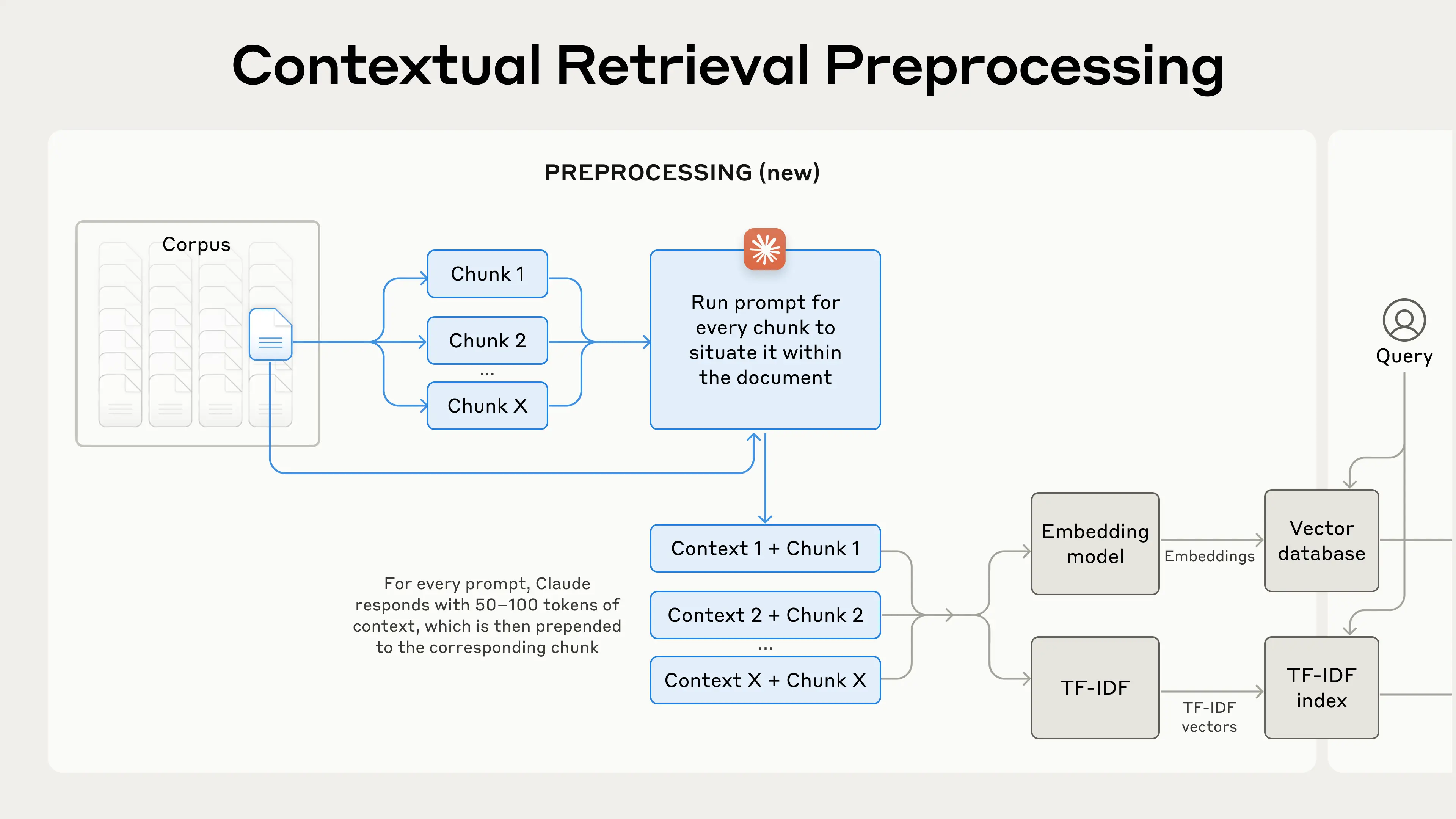
第4章:Contextual Retrievalの解決策
核心アイデア
各チャンクに「文脈説明」を追加してからEmbeddingとBM25インデックスを作成する
【Before:従来のチャンク】
「会社の売上は前四半期比3%成長しました。」
【After:文脈化されたチャンク】
「このチャンクはACME社の2023年Q2業績に関するSEC提出書類からの
抜粋です。前四半期の売上高は3億1400万ドルでした。
会社の売上は前四半期比3%成長しました。」
文脈をどうやって生成するか?
数千〜数百万のチャンクを人手で注釈するのは不可能です。そこでClaudeを使って自動生成します。
使用するプロンプト:
<document>
{{ドキュメント全体}}
</document>
以下のチャンクをドキュメント全体の中で位置づけてください
<chunk>
{{チャンクの内容}}
</chunk>
検索精度向上のため、このチャンクを文脈づける簡潔な説明を
書いてください。説明のみを回答してください。
生成される文脈は通常50〜100トークン(数十語程度)で、チャンクの先頭に追加されます。
改善後の RAG の仕組み
第5章:コスト効率を実現する「Prompt Caching」
普通にやると高コスト?
各チャンクに文脈を生成するには、「ドキュメント全体」を毎回読み込む必要があります。
数百チャンクがあると、同じドキュメントを数百回読み込むことに…
プロンプトキャッシングによる解決
Claudeの「プロンプトキャッシング」機能を使うと:
- ドキュメント全体を一度だけキャッシュに読み込む
- 各チャンクの処理時はキャッシュを参照するだけ
結果:100万トークンあたり約$1.02という低コストで文脈化が可能
第6章:実験結果
| 手法 | 検索失敗率 | 改善率 |
|---|---|---|
| 従来のEmbedding | 5.7% | — |
| Contextual Embedding | 3.7% | 35%改善 |
| Contextual Embedding + Contextual BM25 | 2.9% | 49%改善 |
| 上記 + Reranking | 1.9% | 67%改善 |
第7章:さらなる改善「Reranking」
Rerankingとは
初期検索で大量のチャンク(例:150個)を取得した後、関連性が薄いチャンクまで取得され、後の回答生成 AI モデルが混乱を招く恐れがあります。これを防ぐため専用のモデルで再評価して本当に関連性の高いものだけを残す技術です。
処理フロー
1. 初期検索 → Top 150チャンクを取得
2. Rerankingモデルに150チャンク + ユーザークエリを再ランキングモデルに渡す
3. 各チャンクに関連性スコアを付与
4. Top 20のみを選抜 → 回答生成 AI に渡す
メリットとトレードオフ
メリット:
- 検索精度がさらに向上(67%改善を達成)
- AIに渡す情報が厳選される → コスト削減、レイテンシ改善
トレードオフ:
- 追加の処理ステップ → わずかな遅延
- Rerankingするチャンク数が多いほど精度UP、だが処理時間もUP
第8章:実装のポイント
1. チャンクの分割方法
- チャンクサイズ、境界、オーバーラップの設定が性能に影響
- 用途に応じて実験が必要
2. Embeddingモデルの選択
- 実験ではGemini Text 004とVoyageが高性能
- モデルによって文脈化の恩恵が異なる
3. 文脈生成プロンプトのカスタマイズ
- ドメイン固有の用語集を追加するなど、調整で精度向上の余地あり
4. チャンク数の設定
- Top-20を使用すると最も高性能(Top-5, Top-10より優れる)
- ただし多すぎるとAIが混乱する可能性も